


OpenAI has recently unveiled a groundbreaking new family of models that are poised to revolutionize the AI landscape. These models, collectively known as OpenAI o1, have been released on the ChatGPT Plus subscription tier, promising significant enhancements in performance and reasoning capabilities.
In an official blog post, OpenAI stated, “We are introducing OpenAI o1, a new large language model trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers.” This strategic move has been eagerly anticipated by AI industry experts, who have been speculating about a new model dubbed the “strawberry” series from OpenAI for weeks.
The new family of models represents a significant leap forward in AI capabilities, prompting OpenAI to deviate from their usual naming convention and reset the series count to one, hence the name OpenAI o1. These models are designed to excel in complex reasoning tasks and employ a unique “chain-of-thought” reasoning approach that sets them apart from previous iterations.
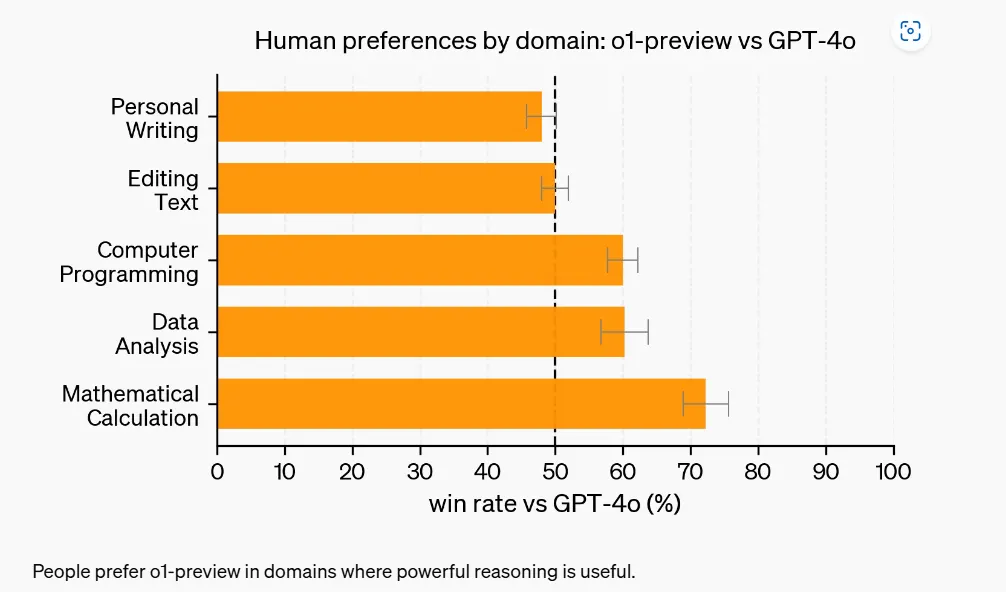
A key feature of the o1 models is their deliberate approach to thinking before acting, enabling them to tackle intricate tasks with precision. Surprisingly, even the smallest model in this new lineup outperforms the top-tier GPT-4o in various domains, as demonstrated in AI testing benchmarks shared by OpenAI.
The emphasis on deliberative reasoning in these models enables them to provide more thoughtful and coherent responses, particularly in tasks that require extensive reasoning. Internal testing by OpenAI has showcased significant improvements in coding, calculus, and data analysis tasks compared to the GPT-4o, although creative tasks like creative writing still show room for improvement.
The new models employ a chain-of-thought AI process during inference, where they methodically work through a problem step by step to arrive at a final result. This approach aims to enhance the model’s reasoning capabilities and provide users with more accurate and insightful responses.
OpenAI’s deliberate training of the o1 models with reinforcement learning to reason using a chain of thought has the potential to unlock significant benefits while also posing risks associated with heightened intelligence. This unique methodology sets the o1 models apart from previous AI architectures and lays the foundation for future advancements in complex reasoning tasks.
While the model’s architecture and reasoning approach have sparked technical debates, OpenAI’s focus on embedding guidelines into the chain-of-thought process ensures greater accuracy and safeguards against potential security breaches. The meticulous reasoning process implemented in these models not only enhances their performance but also minimizes the risks associated with AI technologies.
Previously, the Reflection AI model had explored a similar reasoning-intensive approach but faced criticism for lack of transparency. By leveraging a chain-of-thought AI process, OpenAI’s o1 models aim to address these concerns and deliver more comprehensive and coherent responses in complex tasks.
By embedding more guidelines into the chain-of-thought process, OpenAI’s models are not only accurate but also less vulnerable to malicious tactics. This meticulous approach allows the models to detect potential risks and counteract them effectively.
Source link




 Will Be Listed on Binance HODLer Airdrops!")










